Introducing our AI Inference Pipeline
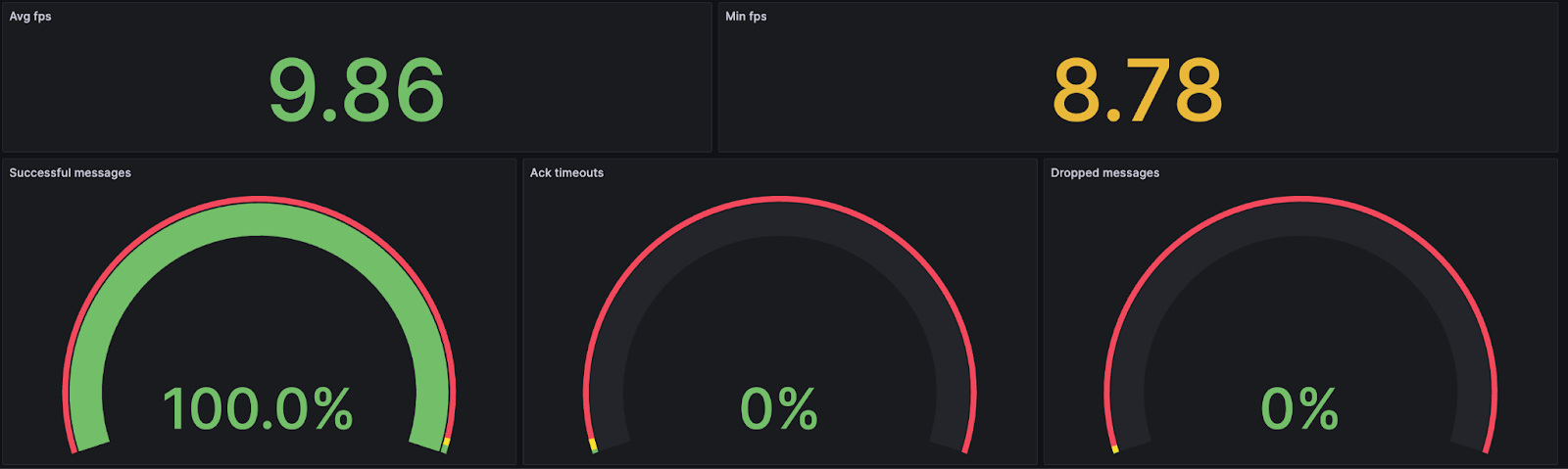
At Teton, we are dedicated to create a reliable, real-time solution that enables staff to promptly respond to patient falls or better yet, to intervene and prevent them. We are proud to provide a service that protects residents’ privacy and that runs 24/7 even in areas with poor internet connectivity. We have achieved this by running our AI inference locally on an Nvidia Jetson Orin-NX. Running the inference locally means that image data never leaves the room, both reducing the need for high-speed internet while ensuring privacy and reliability.
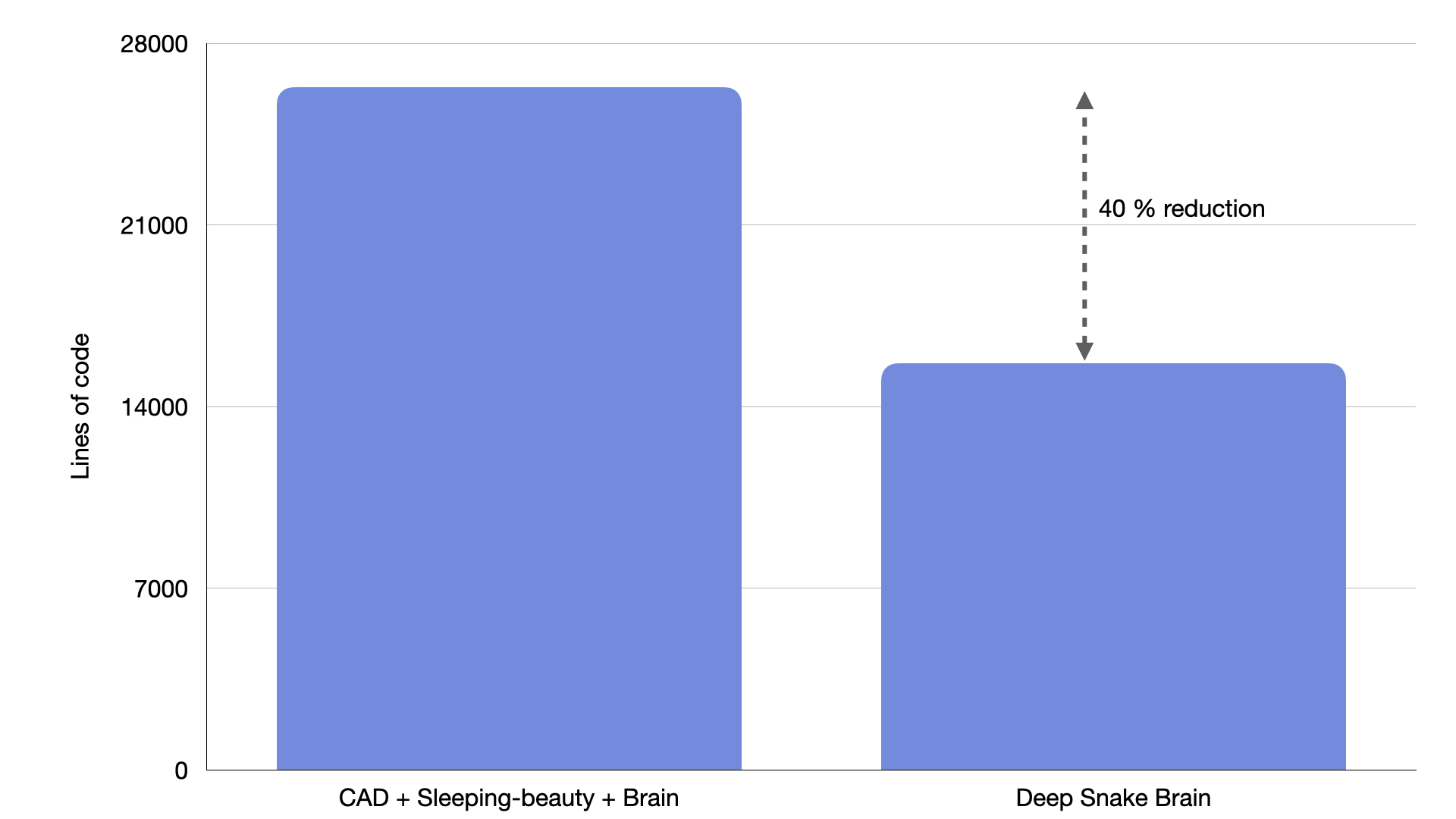
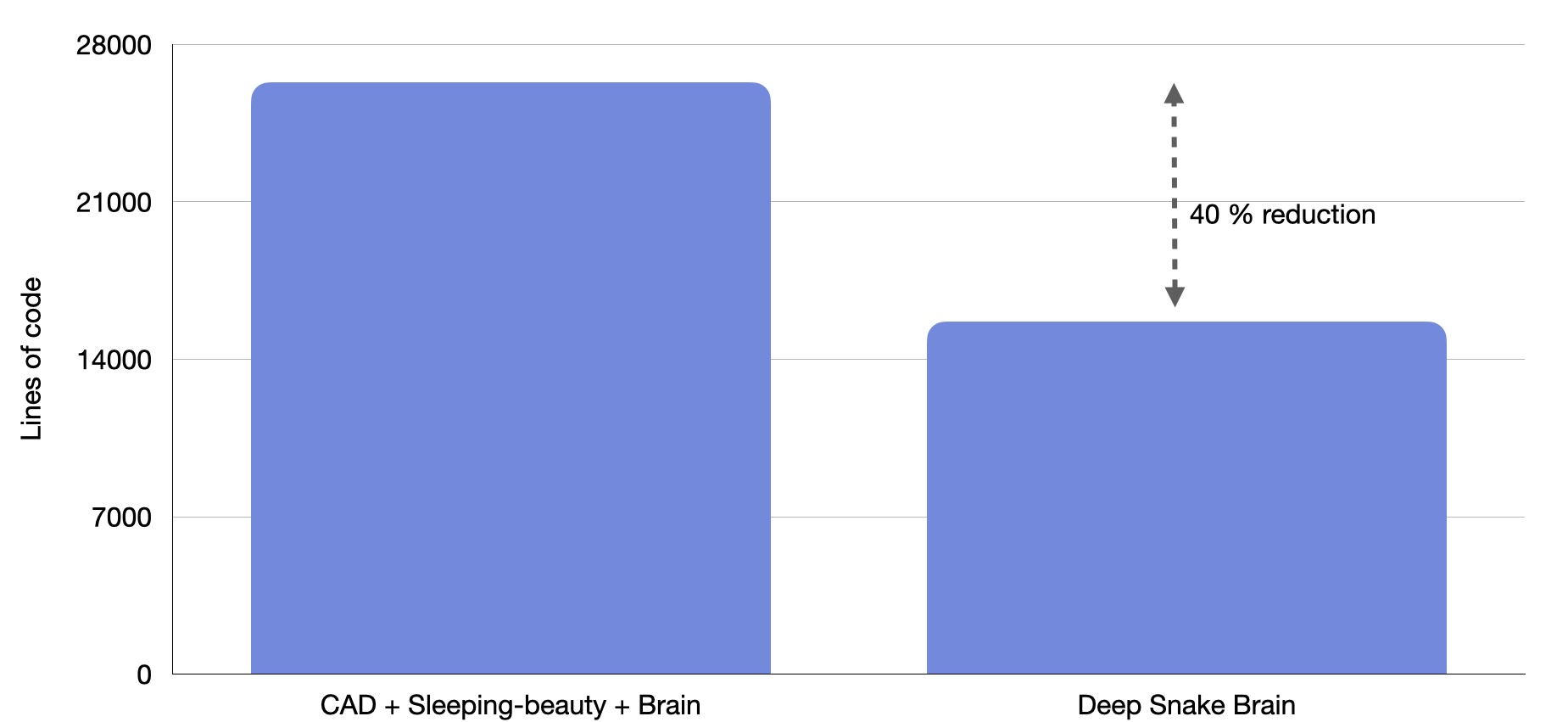
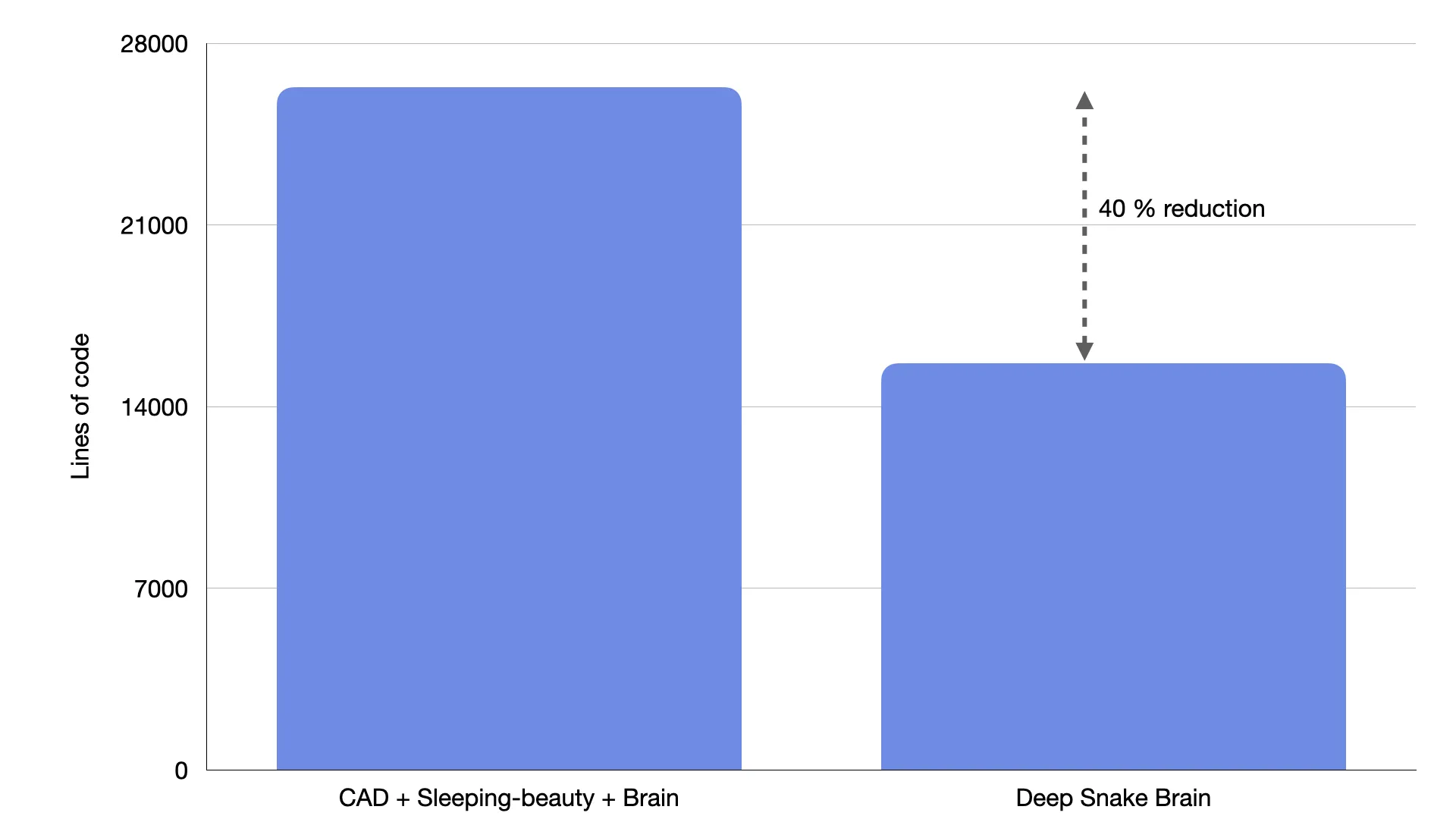
In the last months, we have revamped our inference pipeline. In this post, we’ll walk you through the key components of our revamped inference pipeline. These improvements have enabled us to iterate faster, made our pipeline more efficient and reliable, and streamlined debugging and testing processes. But before diving into the changes, let’s first take a look at the status quo just a few months ago.