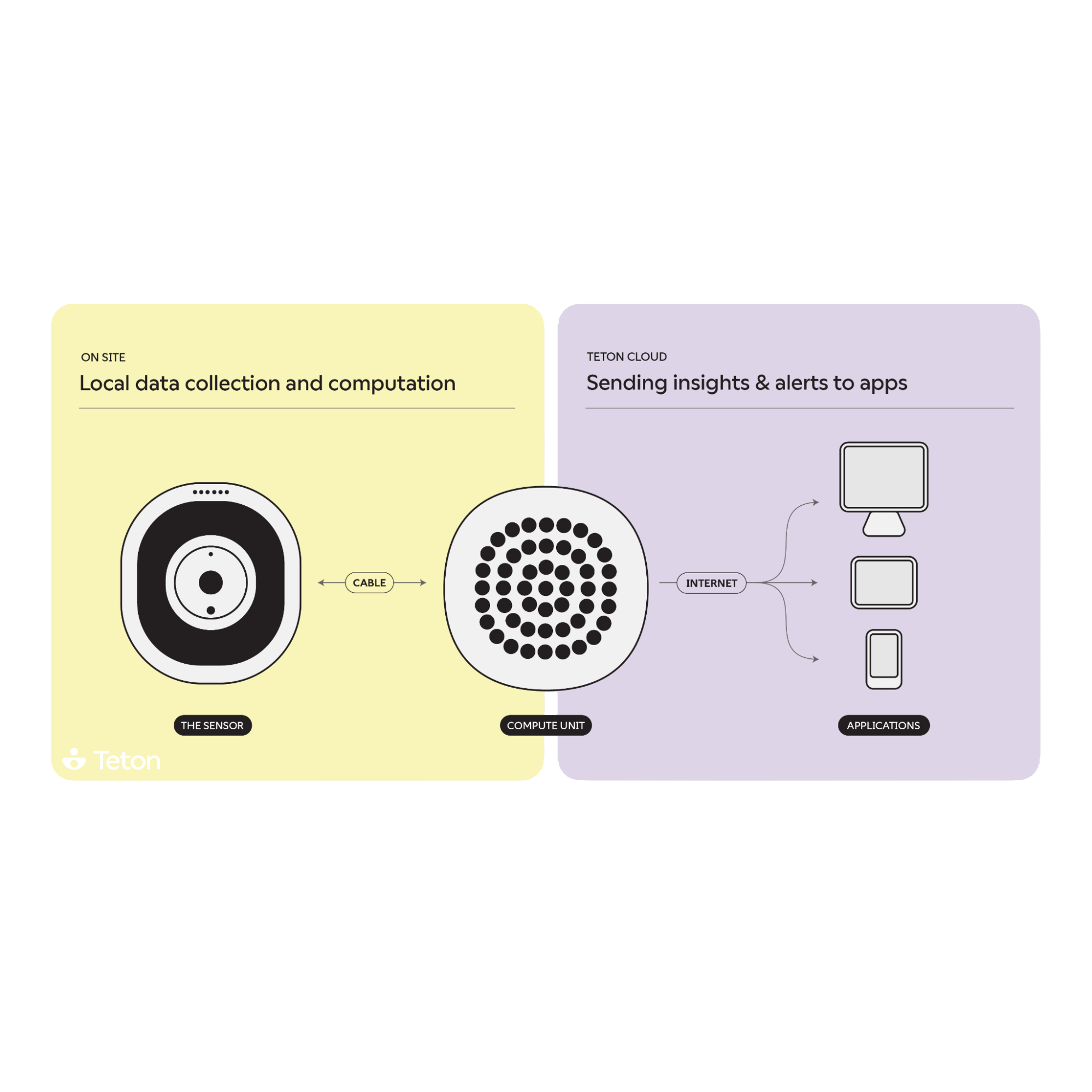
One-click Training

At Teton.ai, we are on a mission to help the healthcare sector address its labor shortage by automating tasks through the use of AI. We're inspired by Tesla's approach to developing self-driving cars: Deep learning, at it's core, is largely an infrastructure problem. In this blog post, we will share our journey towards building an automated data engine and training setup, which we internally refer to as "one-click training."
System and feedback loops
As we began developing our data engine, we quickly realized the importance of robust debugging and monitoring tools. Deep learning models can be challenging to debug, they want to learn and their failures are often silent. To give ourselves the best chance of catching errors, we built an internal tool that streams predictions and provides insight into the performance of the system. This tool also helps us identify data triggers that can capture valuable, rare events that are crucial for training the model.

Data Sources
Obtaining data in the healthcare sector can be challenging, but we found innovative ways to access the information we needed. (Check out Julius' blog post about one such method.) Our dataset now contains 1.7 million images. However, we quickly learned that quality trumps quantity. Only about 0.1% of raw video data was worth annotating, so we had to carefully choose which data to include in our training set. To pinpoint the most valuable data, we used data triggers based on temporal inconsistencies and simple heuristics like flicker detection and conflicting predictions from different models. We also experimented with more sophisticated approaches like GANs and autoencoders to enhance our data triggers.

DataPipeline
Once we had identified the data we wanted to include in our training set, we needed to develop a pipeline to efficiently process it. In the past, we used the COCO format, it uses one annotation file which is fine if the dataset is static, but merging datasets and updating them as we did was nerve-racking and error-prone, instead we decided to move towards a more modular approach. Another reason why one big annotation file is a bad idea is that Pytorch Workers will (in DDP Mode) copy the init of the dataloader, this will cause timeout for the worker when the annotation files reach a certain size, loading annotations in getitem() is fast enough.
We organize our data into small video clips and corresponding annotation files. This data format allow us to more easily track the progress of the samples in different stages of the data pipeline, from fetching raw video and extracting images and metadata, to autolabelling and human review, before finally uploading the data to our training server. We use a combination of Python and cronjobs to automate as much of the process as possible, freeing up developer time and enabling us to scale more efficiently.
AutoLabelling
Human labor is slow and expensive and being able the spin the data engine as fast as possible is key. We tried to use some of these annotation farms but was dissatisfied with quality and speed. Therefore we put a lot of work in to automatically creating labels and only using highly skilled annotators to review and finetune these annotations. The pipeline works as follows: Each clip is fetched from the server and passed through different SOTA detectors trained on our custom data, using the benefits of hindsight in offline processing we are able to create densely annotated clips for free. Next these clips get sent to our annotation platforms, we use both Encord and our own customer platform, where annotators can add missing labels or correct existing ones. These platforms are only managed by 2 annotators and are producing 6000-8000 annotated images per day. Other than our annotators, the entire process is automated with cronjobs. The autolabelling models are an iterative loop in it self, when they get better we can produce more labelled data at increasingly lower costs.

Conclusion
Through our quest for one-click training, we have developed a robust data engine for healthcare that is able to efficiently process large volumes of data and automate many of the tasks involved in reating a successful AI system. Every week we just run train.py and our models get better.